Task
ComfyUI Tutorial for Architecture: From Sketch to Realistic Render with ControlNet Canny
If you want to transform a simple sketch or plan into a detailed and realistic architectural render, ComfyUI, with its modular structure, is the perfect tool for this. In this tutorial, we will explore a simple yet powerful workflow using ControlNet Canny to turn a basic drawing into a high-quality image.
This tutorial is designed for beginners with ComfyUI. We will walk through each step, from importing models to achieving the final result.
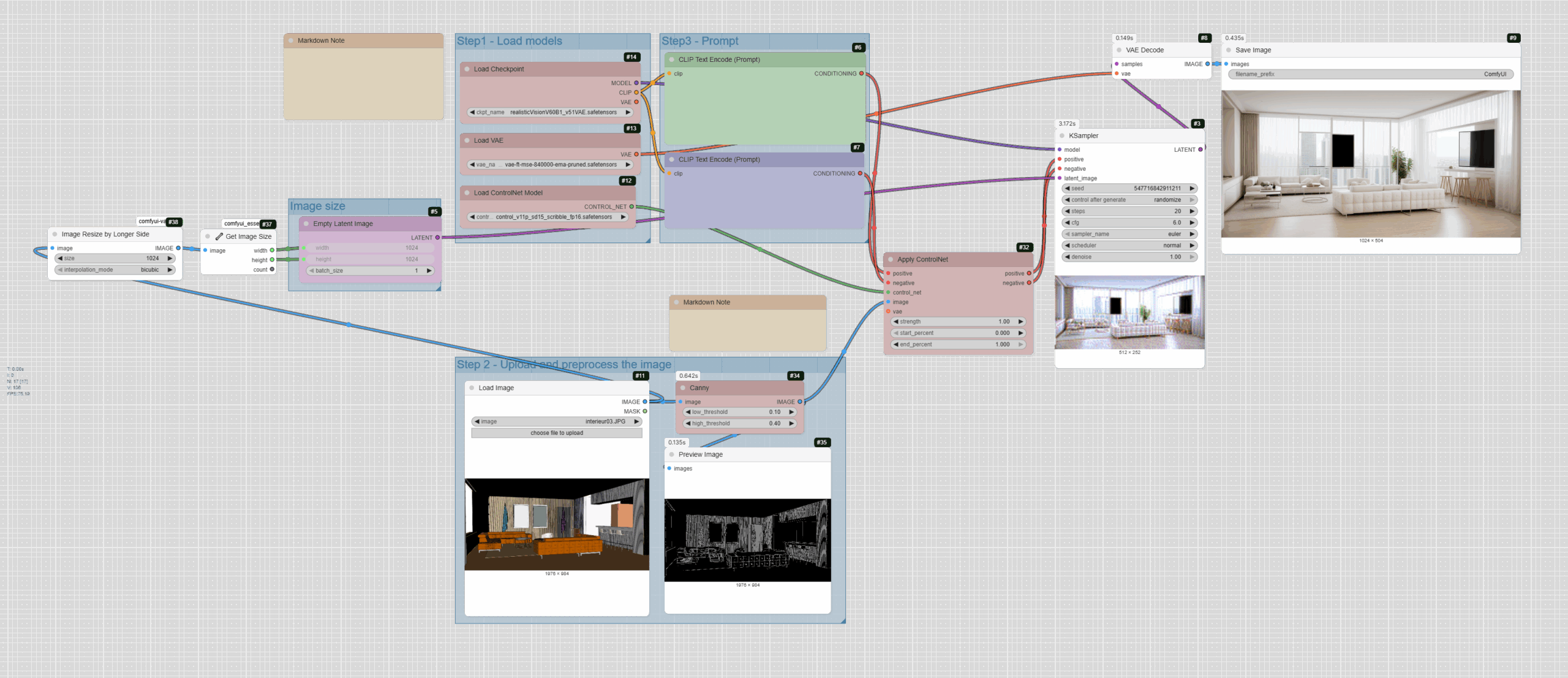
The Step-by-Step Workflow
Here is a general overview of the workflow we will use. Each group of nodes represents a logical step in the process.
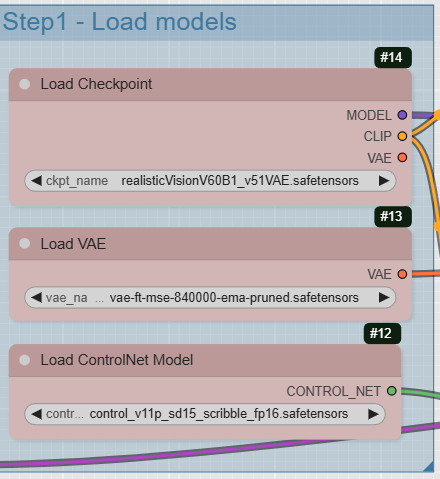
Step 1: Load Models
The first step is to load all the necessary models and tools for the process to work.
- CheckpointLoaderSimple: This is the core of our workflow. This node loads a Stable Diffusion model. This model understands our text « prompt » and generates the image. For architecture and renders, models like « DreamShaper » or « realisticVision » are excellent choices. This node provides three outputs: the
MODEL (the base model), the CLIP (the text encoder that interprets our instructions), and the VAE (the decoder that transforms the latent image into the final image).
- VAELoader: Although CheckpointLoaderSimple can load a default VAE, it is often better to load a separate one for higher quality. The VAE (Variational AutoEncoder) is essential for the decoding phase, as it converts the abstract latent space into a readable image.
- ControlNetLoader: This node is the key component of our process. It loads a ControlNet model, which will guide the image generation based on an input image. In this case, the « Canny » model is ideal for preserving the contours and lines of our architectural drawing.
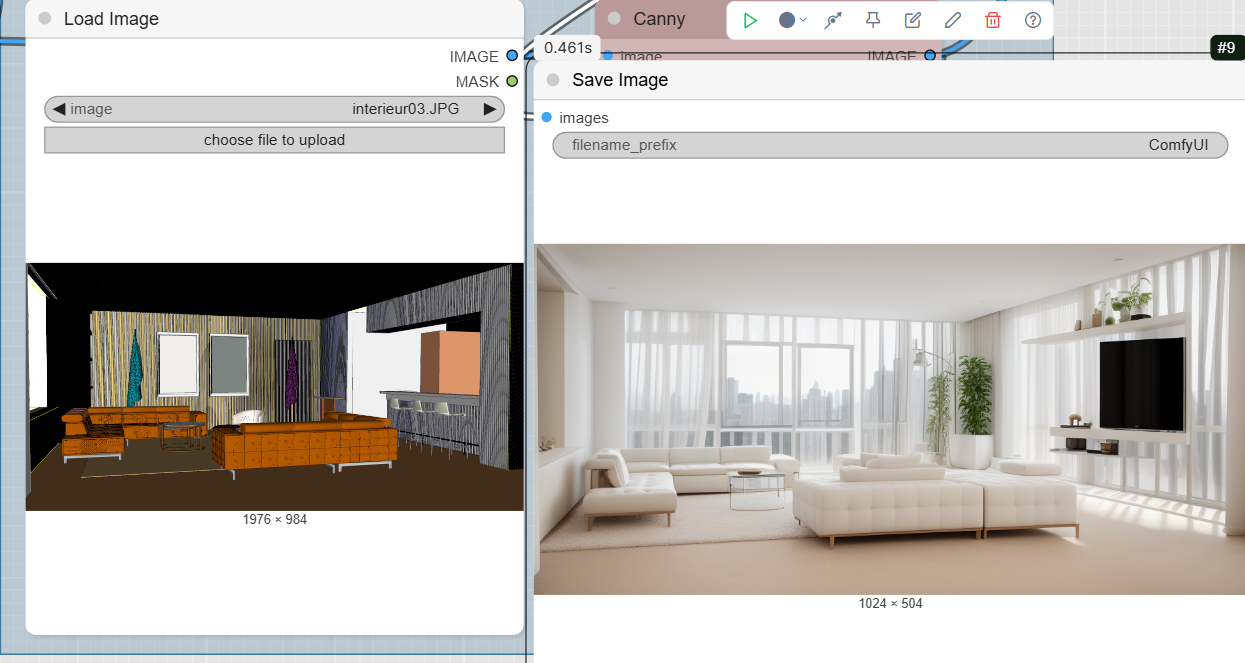
Step 2: Prepare the Input Image
This section handles importing your sketch and processing it so it can be understood by ControlNet.
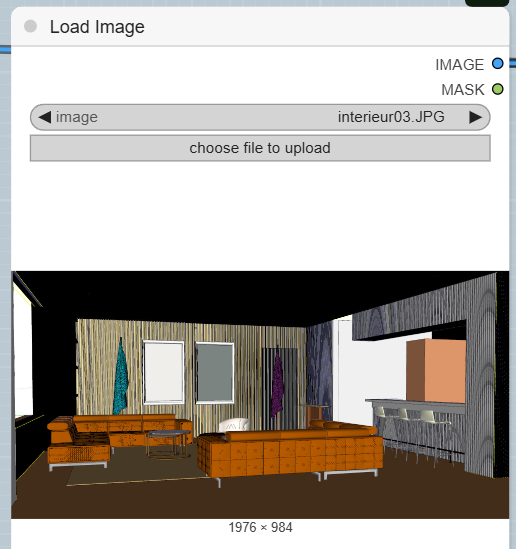
- LoadImage: This is where you upload your sketch or plan. Choose your file, such as a facade sketch or an interior drawing.
- Canny: This node is a « preprocessor ». It takes your input image and extracts its contours and edges. The Canny model is excellent for accurately capturing architectural lines. You can adjust the thresholds (
low_threshold and high_threshold) to control the fineness of the detected edges. The other two nodes connected to it,

GetImageSize+ and JWImageResizeByLongerSide, automatically resize and define the image dimensions, ensuring your base image is suitable for the model.
- PreviewImage: Although not essential for the final result, this node is very useful for visualizing the output of the Canny preprocessor in real time. This way, you can see what the contours that ControlNet will use as a guide look like.

Step 3: Enter Instructions (Prompt)
This step is crucial for telling the model what you want to generate.
- CLIPTextEncode (positive): This is your « positive prompt ». Here, you describe in detail the image you want to obtain. Feel free to be very specific about the style (modern, minimalist), materials (wood, concrete), lighting (natural, soft), and atmosphere. Use keywords that evoke well-known references like « architectural digest » or « professional photography ».
- CLIPTextEncode (negative): This is your « negative prompt ». It is used to tell the model what you do not want to see in the result. For example, rendering flaws (« blurry », « low quality »), undesirable colors (« oversaturated colors »), or non-architectural elements (« cartoon », « anime »).

Step 4: The Generation Process (KSampler & Final Output)
This last part assembles all the elements to create the final image.
- ControlNetApplyAdvanced: This node receives the positive and negative prompts, as well as the contours of your image (output of the Canny node). It applies the ControlNet model to combine the influence of your prompts with the information from your initial drawing. The outputs of this node are the « conditions » for our process, which tell the KSampler how to behave.
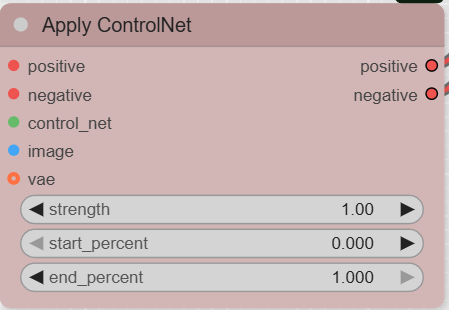
- EmptyLatentImage: This node creates an « empty » image in the latent space, which will serve as the starting point for generation. The dimensions of this image are automatically defined by the
In this example, we resize the image according to the input image.
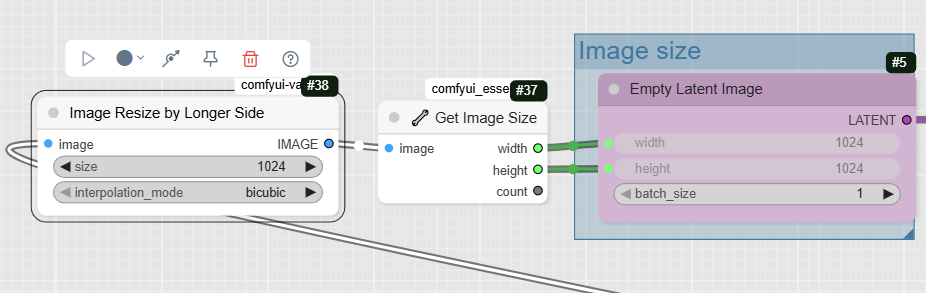 GetImageSize+ node to match your input image.
GetImageSize+ node to match your input image.
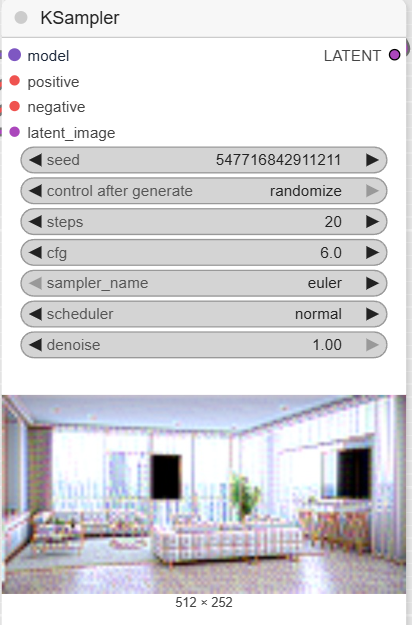
- KSampler: This is the generation engine. The KSampler takes the model, the conditions (prompts), and the empty latent image to generate a new latent image, following the given instructions. You can adjust key parameters here such as the seed (for reproducibility), the steps (quality), and the cfg (the level of prompt adherence).
- VAEDecode: Once the KSampler has generated the latent image, this node uses the VAE (which we loaded at the beginning) to decode this latent image and transform it into a visible color image.
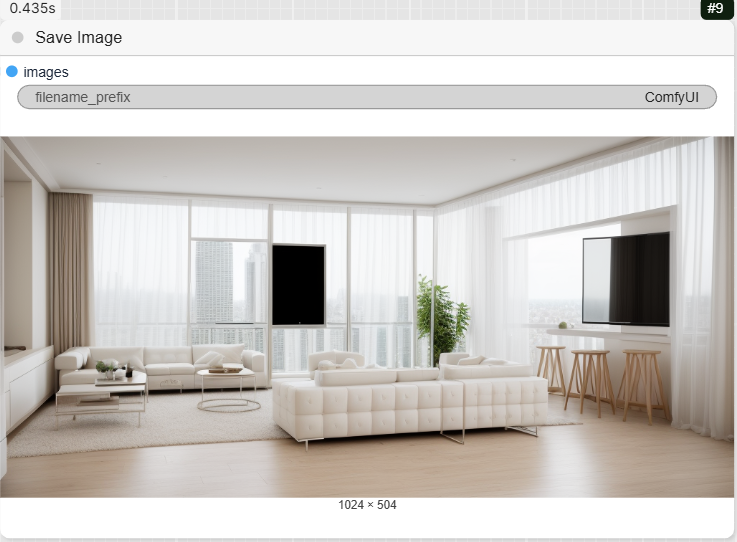
- SaveImage: Finally, this node saves the final render to your computer.
Tips for Architecture with ComfyUI
- Be precise in your prompts: The more detailed your description, the more the result will match your vision.
- Use quality base images: Even if Canny can extract contours, a clear base drawing without unnecessary elements will yield better results.
- Test different models: Feel free to try other Stable Diffusion and ControlNet models to find the one that best suits your architectural style.
French translation
Étape 1 : Chargement des Modèles (Load Models)
La première étape consiste à charger tous les modèles et outils nécessaires pour que le processus fonctionne.
- CheckpointLoaderSimple : C’est le cœur de notre workflow. Ce nœud charge un modèle de diffusion stable (Stable Diffusion). C’est ce modèle qui comprendra notre « prompt » (texte) et générera l’image. Pour l’architecture et les rendus, les modèles comme « DreamShaper » ou « realisticVision » sont d’excellents choix. Ce nœud fournit trois sorties : le
MODEL (le modèle de base), le CLIP (l’encodeur de texte qui interprète nos instructions), et le VAE (le décodeur qui transforme l’image latente en image finale).
- VAELoader : Bien que le CheckpointLoaderSimple puisse charger un VAE par défaut, il est souvent préférable d’en charger un séparément pour une meilleure qualité. Le VAE (Variational AutoEncoder) est essentiel pour la phase de décodage, car il convertit l’espace latent abstrait en une image lisible.
- ControlNetLoader : Ce nœud est l’élément clé de notre processus. Il charge un modèle ControlNet, qui permettra de guider la génération de l’image en se basant sur une image d’entrée. Dans ce cas, le modèle « Canny » est idéal pour préserver les contours et les lignes de notre dessin architectural.
Étape 2 : Préparation de l’Image d’Entrée (Preprocess the Image)
Cette section gère l’importation de votre esquisse et son traitement pour qu’elle puisse être comprise par ControlNet.
- LoadImage : C’est ici que vous téléchargez votre esquisse ou votre plan. Choisissez votre fichier, comme une esquisse de façade ou un dessin intérieur.
- Canny : Ce nœud est un « préprocesseur ». Il prend votre image d’entrée et en extrait les contours et les bords. Le modèle Canny est excellent pour capturer les lignes architecturales de manière précise. Vous pouvez ajuster les seuils (low_threshold et high_threshold) pour contrôler la finesse des bords détectés. Les deux autres nœuds qui lui sont connectés,
GetImageSize+ et JWImageResizeByLongerSide permettent de redimensionner et de définir les dimensions de l’image de manière automatique, garantissant que votre image de base est adaptée au modèle.
- PreviewImage : Ce nœud, bien que non indispensable au résultat final, est très utile pour visualiser en temps réel le résultat du préprocesseur Canny. Vous verrez ainsi à quoi ressemblent les contours que ControlNet utilisera comme guide.
Étape 3 : Saisie des Instructions (Prompt)
Cette étape est cruciale pour indiquer au modèle ce que vous voulez générer.
- CLIPTextEncode (positif) : C’est votre « prompt positif ». C’est ici que vous décrivez en détail l’image que vous souhaitez obtenir. N’hésitez pas à être très précis sur le style (moderne, minimaliste), les matériaux (bois, béton), l’éclairage (naturel, doux), et l’ambiance. Utilisez des mots-clés qui évoquent des références connues comme « architectural digest » ou « professional photography ».
- CLIPTextEncode (négatif) : C’est votre « prompt négatif ». Il sert à indiquer au modèle ce que vous ne voulez pas voir dans le résultat. Par exemple, des défauts de rendu (« blurry », « low quality »), des couleurs indésirables (« oversaturated colors ») ou des éléments non architecturaux (« cartoon », « anime »).
Étape 4 : Le Processus de Génération (KSampler & Final Output)
Cette dernière partie assemble tous les éléments pour créer l’image finale.
- ControlNetApplyAdvanced : Ce nœud reçoit les prompts positifs et négatifs, ainsi que les contours de votre image (sortie du nœud Canny). Il applique le modèle ControlNet pour combiner l’influence de vos prompts avec les informations de votre dessin initial. Les sorties de ce nœud sont les « conditions » de notre processus, qui indiquent au KSampler comment se comporter.
- EmptyLatentImage : Ce nœud crée une image « vide » dans l’espace latent, qui servira de point de départ pour la génération. Les dimensions de cette image sont automatiquement définies par le nœud
GetImageSize+ pour correspondre à votre image d’entrée.
- KSampler : C’est le moteur de la génération. Le KSampler prend le modèle, les conditions (prompts), et l’image latente vide pour générer une nouvelle image latente, en suivant les instructions données. Vous pouvez y régler des paramètres clés comme le
seed (pour la reproductibilité), les steps (la qualité), et le cfg (le niveau de respect du prompt).
- VAEDecode : Une fois que le KSampler a généré l’image latente, ce nœud utilise le VAE (que nous avons chargé au début) pour décoder cette image latente et la transformer en une image couleur visible.
- SaveImage : Enfin, ce nœud enregistre le rendu final sur votre ordinateur.
Conseils pour l’Architecture avec ComfyUI
- Soyez précis dans vos prompts : Plus votre description est détaillée, plus le résultat sera conforme à votre vision.
- Utilisez des images de base de qualité : Même si Canny peut extraire les contours, un dessin de base clair et sans éléments inutiles donnera de meilleurs résultats.
- Testez différents modèles : N’hésitez pas à essayer d’autres modèles de diffusion stable et de ControlNet pour trouver celui qui correspond le mieux à votre style architectural.
Modèles
- Modèle de Checkpoint (modèle principal de Stable Diffusion) : realisticVisionV60B1_v51VAE.safetensors
- Modèle ControlNet : control_v11p_sd15_scribble_fp16.safetensors
- Modèle VAE : vae-ft-mse-840000-ema-pruned.safetensors