Task
ComfyUI Architectural Tutorial: Photorealistic Rendering with the Gemini 2.0 Flash Model
In the world of architectural design, speed and flexibility are essential. With the integration of multimodal models like Gemini 2.0 Flash into ComfyUI, it is now possible to merge visual elements, manipulate them with text, and achieve photorealistic renderings in just a few clicks.
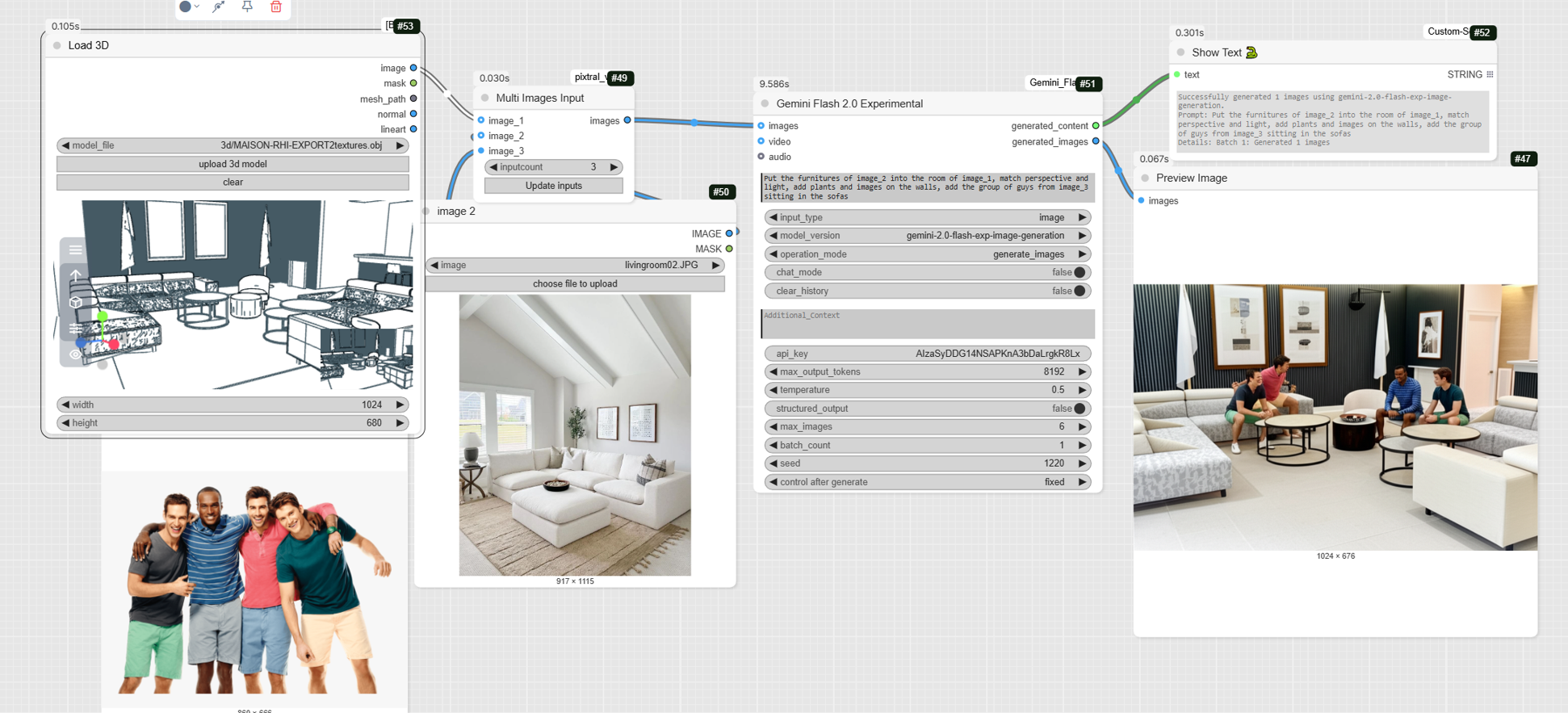
This tutorial explores a unique workflow that uses Gemini 2.0 Flash to combine multiple images and a 3D model into a coherent and detailed render. ![]()
Disclamer : La génération d’images avec gemini-2.0-flash-preview n’est actuellement pas disponible dans plusieurs pays d’Europe, du Moyen-Orient et d’Afrique. Un VPN permet malgré tout de contourner la restriction.
The Step-by-Step Workflow
Here is an overview of the workflow. This process is linear and aims to merge information from different sources to create a final render.
Step 1: Loading Visual Sources
The first step is to load all the elements we want to combine for our render.
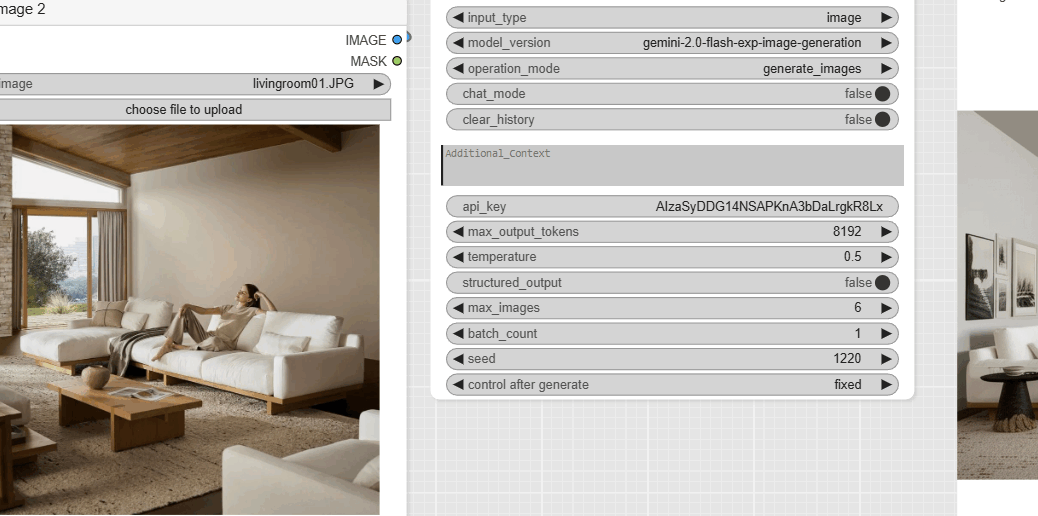
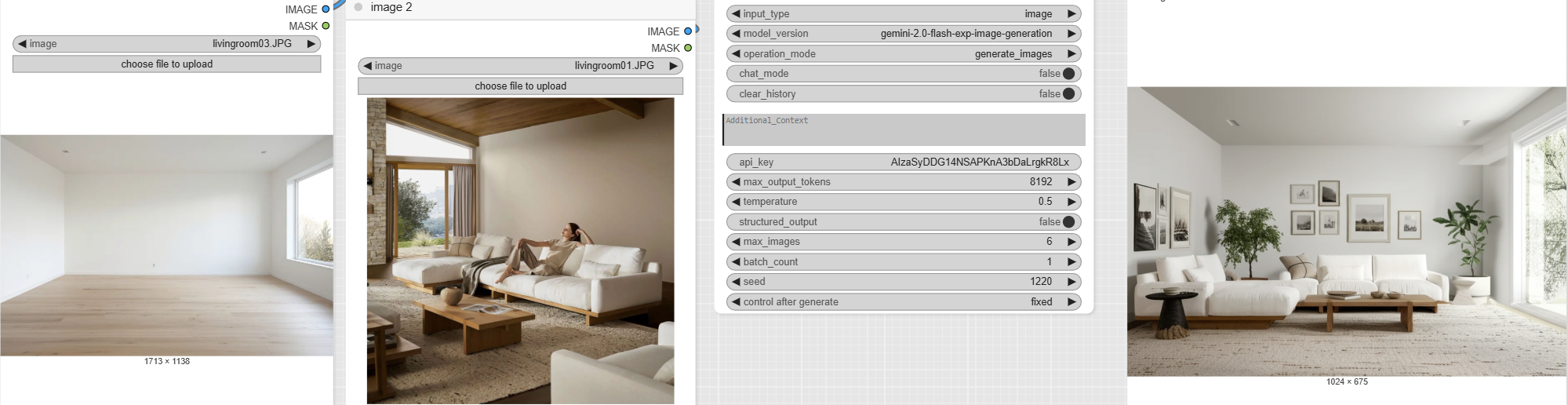
- Load3D (image 1): This node is an innovative starting point. It loads a 3D model (in this case, an .obj file named MAISON-RHI-EXPORT2textures.obj). It generates an image from this 3D model based on defined camera and rendering settings. This is the foundation of our architectural scene. The output of this node will be used as our « image 1 ».
- LoadImage (image 2): This node loads a standard image. In this workflow, the livingroom02.JPG image is imported. It likely contains the furniture we want to integrate into our scene.
- LoadImage (image 3): Another LoadImage node is used to import a third image (group-of-men-png-pluspng-group-of-men.png). This is a group of people who will be added to the final render.
Step 2: Preparing the Input for Gemini
The Gemini 2.0 Flash model is multimodal and capable of processing multiple images at once.
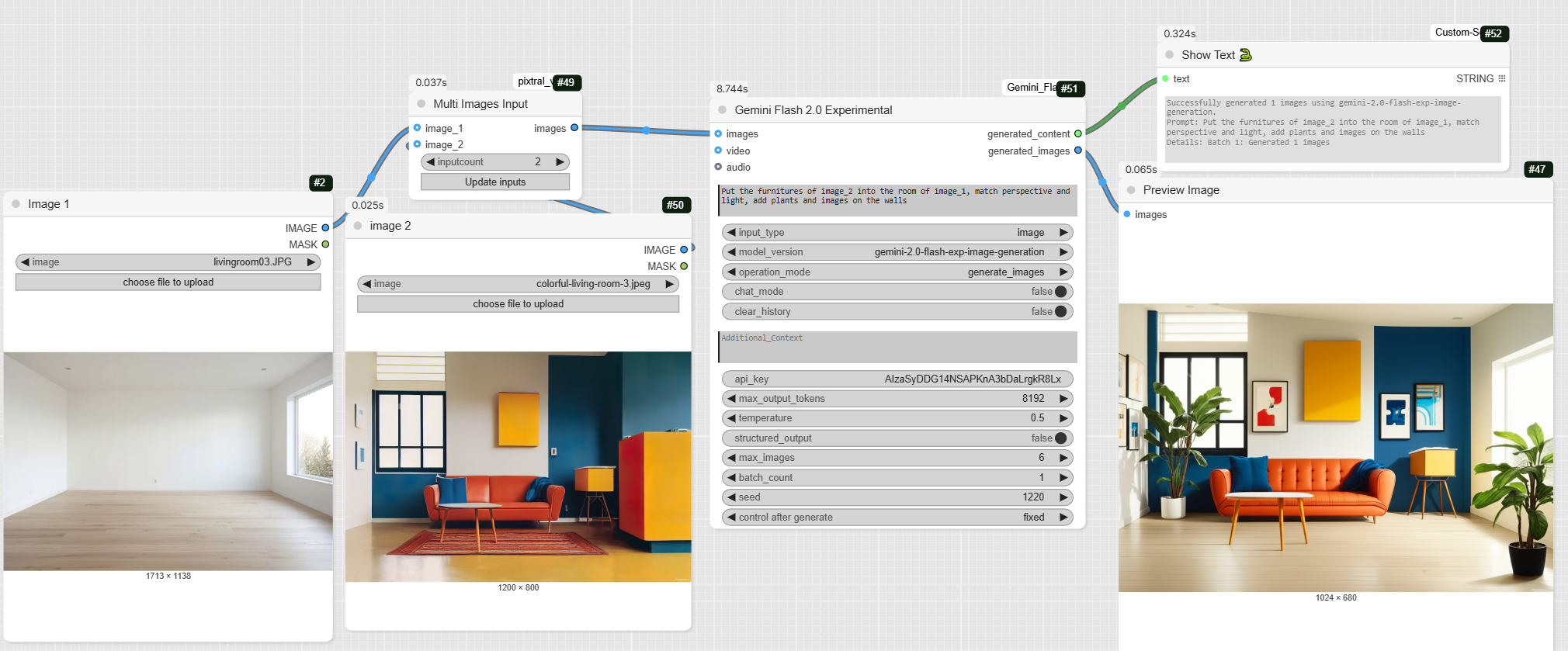
- MultiImagesInput: This node is a preprocessor that gathers our source images. It takes the outputs of the three LoadImage nodes (image 1, image 2, and image 3) and combines them into a single input for the Gemini model. This allows the model to understand the context of each image and use them together.
Step 3: The Gemini Artificial Intelligence
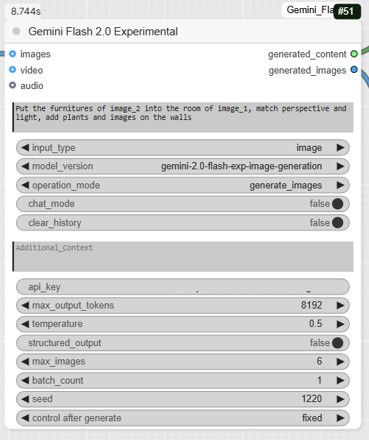
This is where the magic happens. The GeminiFlash node is the core of the workflow, where the image generation takes place.
- GeminiFlash: This node receives the set of images we prepared in the previous step. It also takes a detailed text prompt as input to guide the generation.
- The prompt: « Put the furnitures of image_2 into the room of image_1, match perspective and light, add plants and images on the walls, add the group of guys from image_3 sitting in the sofas ».
- The model: The specified model is gemini-2.0-flash-exp-image-generation, which is a fast and powerful experimental version for image generation.
- The output: This node generates a final image, which is the result of merging all visual sources according to the prompt’s instructions. It also provides a text message that confirms the success of the generation and recalls the parameters used.
Step 4: Visualization and Saving
The final step is to display the result and save it.
- PreviewImage: This node displays the image generated by the Gemini model, allowing you to view it directly in ComfyUI.
- ShowText|pysssss: This node displays the text confirmation message from the Gemini node, which is useful for checking that everything went smoothly.
Tips for Architecture with Gemini Flash
- Detailed Prompts: The power of this workflow lies in the precision of your prompt. Describe exactly how the elements should interact with each other and with the environment.
- Quality of Sources: The better the quality of your images and 3D model, the more impressive the final render will be.
- API Key: Note that this type of workflow requires an API key to access Gemini services, which must be configured in the GeminiFlash node.
3 images input
Traduction Française
Tutoriel ComfyUI pour l’Architecture : Rendu Photographique avec le Modèle Gemini 2.0 Flash
Dans le monde de la conception architecturale, la rapidité et la flexibilité sont essentielles. Avec l’intégration de modèles multimodaux comme Gemini 2.0 Flash dans ComfyUI, il est désormais possible de fusionner des éléments visuels, de les manipuler avec du texte et d’obtenir des rendus photoréalistes en quelques clics.
Ce tutoriel explore un workflow unique qui utilise Gemini 2.0 Flash pour combiner plusieurs images et un modèle 3D en un rendu cohérent et détaillé.
Le Workflow Étape par Étape
Voici un aperçu du workflow. Ce processus est linéaire et vise à fusionner des informations de différentes sources pour créer un rendu final.
Étape 1 : Chargement des Sources Visuelles
La première étape consiste à charger tous les éléments que nous souhaitons combiner pour notre rendu.
- Load3D (image 1) : Ce nœud est un point de départ innovant. Il charge un modèle 3D (ici, un fichier .obj appelé MAISON-RHI-EXPORT2textures.obj). Il génère une image à partir de ce modèle 3D selon des paramètres de caméra et de rendu définis. C’est le fondement de notre scène architecturale. La sortie de ce nœud sera utilisée comme notre « image 1 ».
- LoadImage (image 2) : Ce nœud charge une image standard. Dans ce workflow, l’image livingroom02.JPG est importée. Elle contient probablement les meubles que nous voulons intégrer dans notre scène.
- LoadImage (image 3) : Un autre nœud LoadImage est utilisé pour importer une troisième image (group-of-men-png-pluspng-group-of-men.png). Il s’agit d’un groupe de personnes qui seront ajoutées au rendu final.
Étape 2 : Préparation de l’Entrée pour Gemini
Le modèle Gemini 2.0 Flash est multimodal et capable de traiter plusieurs images en même temps.
- MultiImagesInput : Ce nœud est un préprocesseur qui rassemble nos images sources. Il prend les sorties des trois nœuds LoadImage (image 1, image 2, et image 3) et les combine en une seule entrée pour le modèle Gemini. C’est ce qui permet au modèle de comprendre le contexte de chaque image et de les utiliser ensemble.
Étape 3 : L’Intelligence Artificielle de Gemini
C’est ici que la magie opère. Le nœud GeminiFlash est le cœur du workflow, là où la génération d’images se produit.
- GeminiFlash : Ce nœud reçoit l’ensemble des images que nous avons préparé à l’étape précédente. Il prend également en entrée un prompt textuel très détaillé qui guide la génération.
- Le prompt : « Put the furnitures of image_2 into the room of image_1, match perspective and light, add plants and images on the walls, add the group of guys from image_3 sitting in the sofas » (Mettez les meubles de l’image 2 dans la pièce de l’image 1, faites correspondre la perspective et la lumière, ajoutez des plantes et des tableaux aux murs, ajoutez le groupe de gars de l’image 3 assis dans les canapés).
- Le modèle : Le modèle spécifié est gemini-2.0-flash-exp-image-generation, qui est une version expérimentale rapide et puissante pour la génération d’images.
- La sortie : Ce nœud génère une image finale, qui est l’aboutissement de la fusion de toutes les sources visuelles selon les instructions du prompt. Il fournit également un message texte qui confirme le succès de la génération et rappelle les paramètres utilisés.
Étape 4 : Visualisation et Sauvegarde
La dernière étape consiste à afficher le résultat et à le sauvegarder.
- PreviewImage : Ce nœud affiche l’image générée par le modèle Gemini, vous permettant de la visualiser directement dans ComfyUI.
- ShowText|pysssss : Ce nœud affiche le message texte de confirmation du nœud Gemini, ce qui est utile pour vérifier que tout s’est bien passé.
Conseils pour l’Architecture avec Gemini Flash
- Prompts détaillés : La puissance de ce workflow réside dans la précision de votre prompt. Décrivez exactement comment les éléments doivent interagir entre eux et avec l’environnement.
- Qualité des sources : Plus vos images et votre modèle 3D sont de bonne qualité, plus le rendu final sera impressionnant.
- API Key : Notez que ce type de workflow nécessite une clé API pour accéder aux services de Gemini, qui doit être configurée dans le nœud GeminiFlash.
Ce workflow montre une manière très efficace d’utiliser la puissance de la génération multimodale pour le design architectural, en combinant des rendus 3D, des assets (meubles, personnes) et des instructions textuelles pour créer des visualisations riches et complexes.