

La génération d’images par intelligence artificielle franchit un cap décisif pour la pratique architecturale. Des outils comme ComfyUI permettent aujourd’hui de construire des chaînes de traitement sophistiquées — render photoréaliste, transfert de style, recomposition d’ambiance — en connectant visuellement des nœuds de traitement. Ce billet présente les objectifs de la session exploratoire, les modèles employés, et les cas d’usage concrets testés.
Objectifs de la session
Qu’est-ce que l’on cherche à faire ?
L’ambition de cet atelier est de replacer l’IA générative dans des situations concrètes de travail de projet : partir d’une image existante — esquisse, vue 3D, référence photographique — et la transformer de façon contrôlée pour produire des rendus convaincants, des ambiances réalistes, ou des planches de concours.
ComfyUI s’impose ici comme l’environnement de prédilection : contrairement à des interfaces comme Midjourney, il offre une maîtrise totale du pipeline. Chaque étape est visible, paramétrable, reproductible. On peut injecter des images de référence, contrôler la diffusion, chaîner des modèles spécialisés.
Les cas testés couvrent cinq grandes familles de besoins :
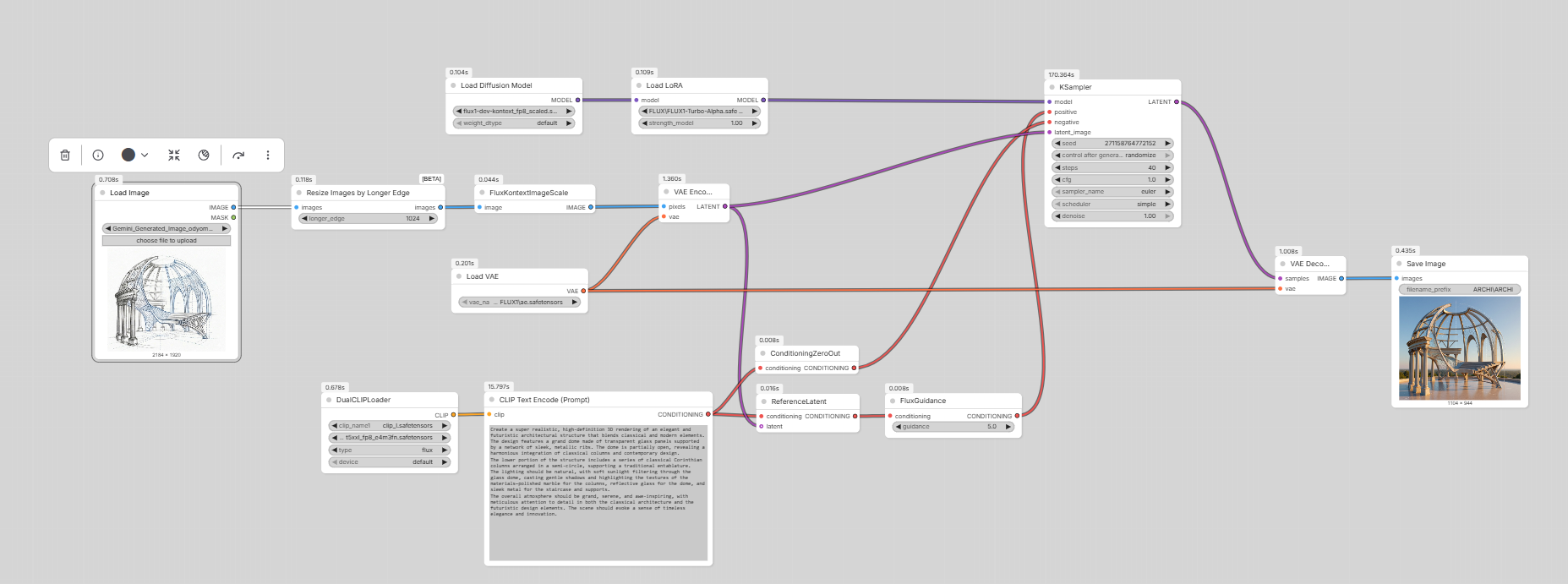
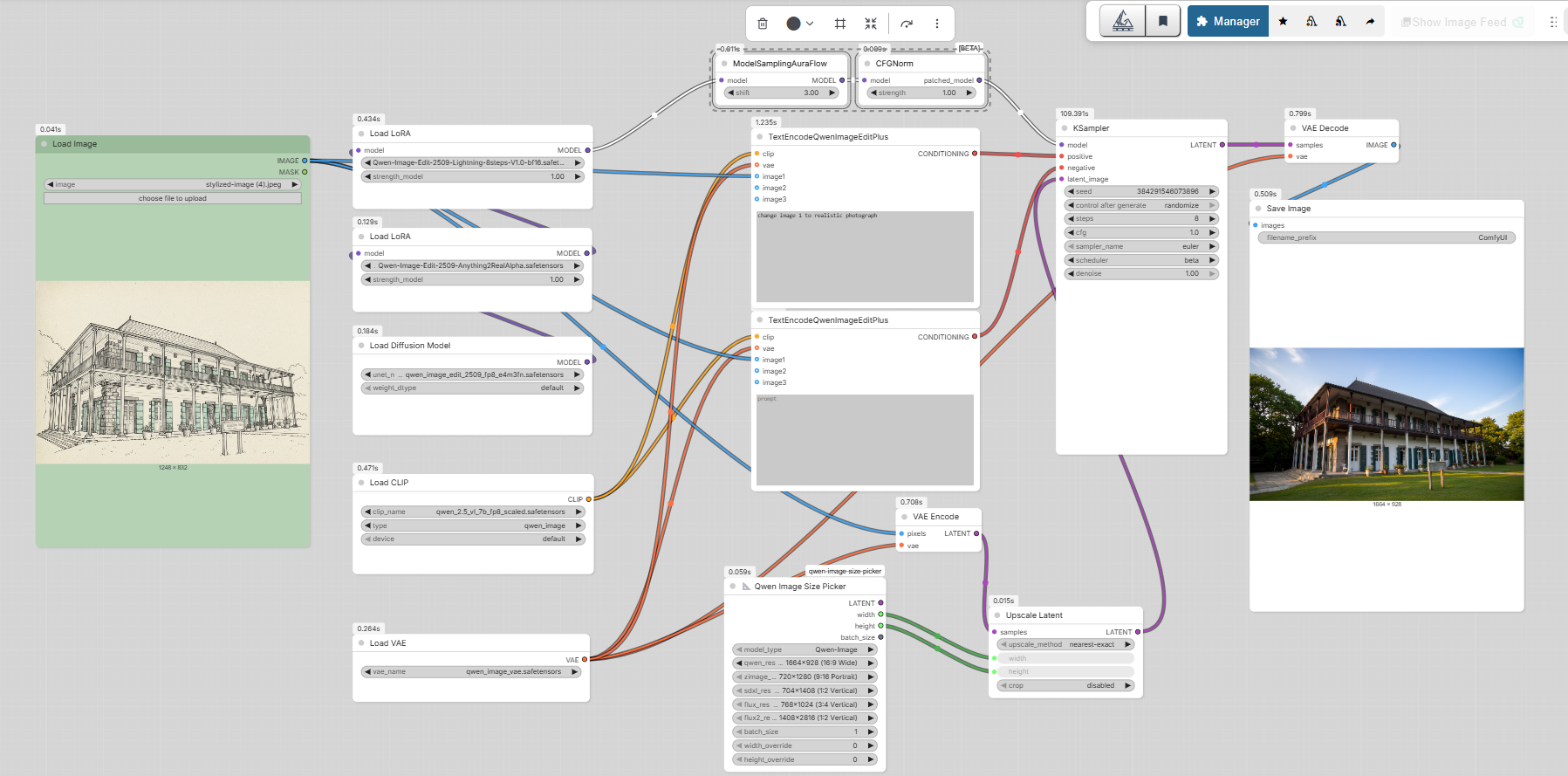
Du dessin au rendu photoréaliste
Transformer une vue 3D filaire ou une esquisse architecturale en photographie réaliste, en conservant la géométrie et les proportions du projet.
01 / Render
Conversion d’un modèle 3D en image photoréaliste. Prompt type : change image 1 to realistic photograph.




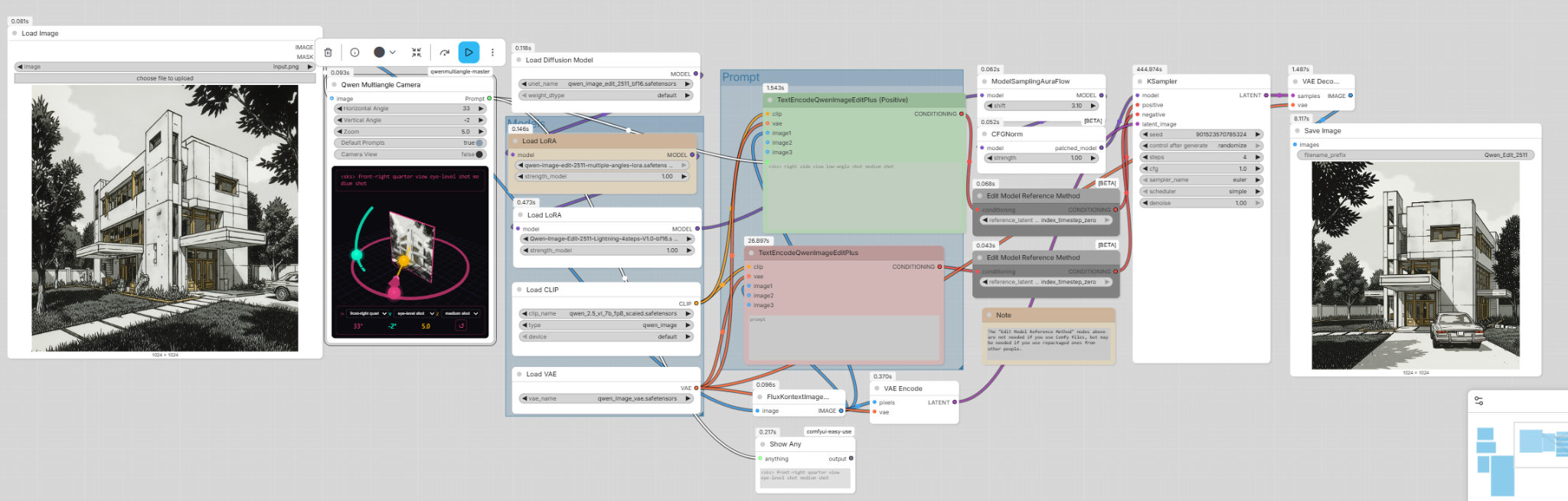
02 / Camera view 3D
Génération de vues alternatives d’un bâtiment à partir d’une image de référence, avec choix du point de vue caméra.


03 / Composition multi-sources
Insertion de mobilier ou d’éléments extérieurs dans une scène existante, avec gestion de l’échelle, de l’orientation et de la lumière.


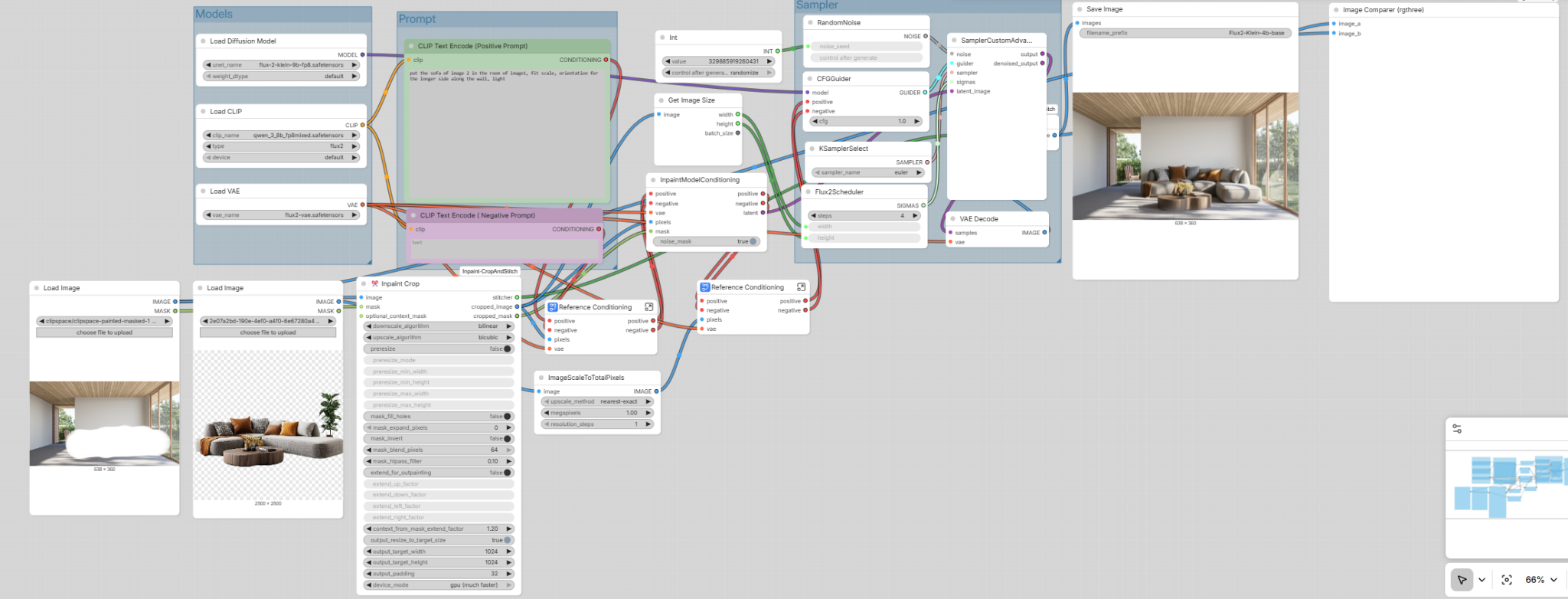
deux souces




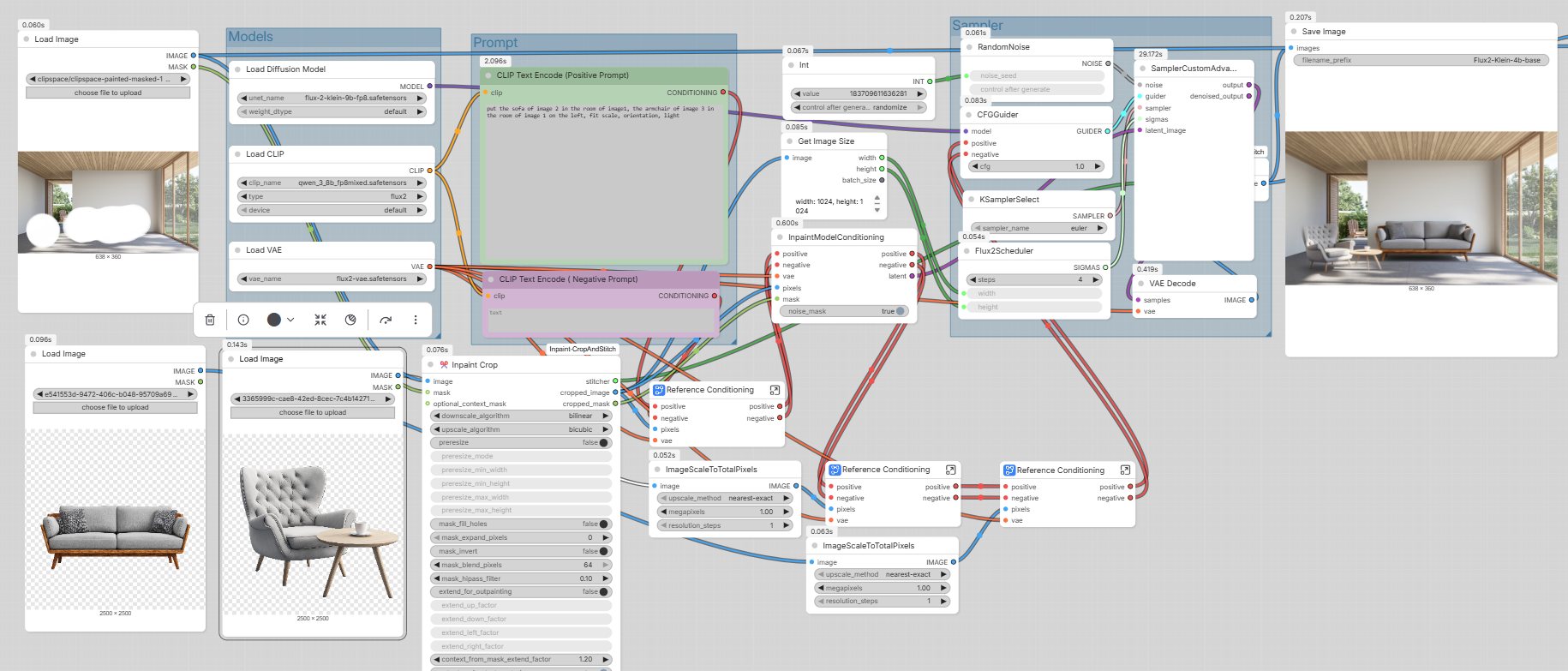
04 / Référence matériaux
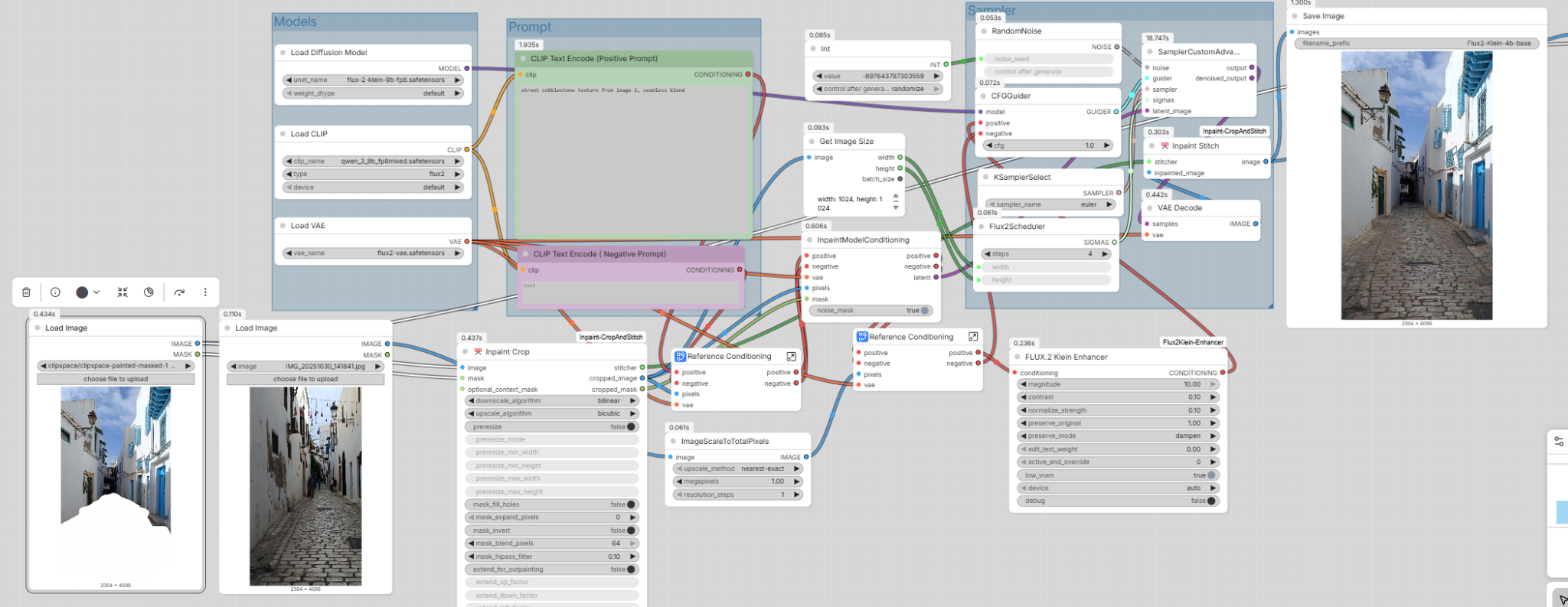
Transfert de texture depuis une image photographique vers un rendu (ex. pavé traditionnel sur une façade), avec blend sans couture.



Important, pour que le transfert de matériaux fonctionne, il faut des références d’échelle. Ici ce sont les fenêtres.



Modification de l’éclairage d’une scène intérieure ou extérieure — heure du jour, ambiance lumineuse — via modèle spécialisé.
Les modèles utilisés
🧠 Modèle de diffusion principal
| Fichier | Type | Nœud |
|---|---|---|
qwen_image_edit_2509_fp8_e4m3fn.safetensors |
Diffusion model (UNet) | UNETLoader |
→ C’est Qwen Image Edit 2509, un modèle d’édition d’images développé par Alibaba/Qwen, quantifié en FP8 pour réduire la VRAM.
📝 Encodeur de texte (CLIP)
| Fichier | Type | Nœud |
|---|---|---|
qwen_2.5_vl_7b_fp8_scaled.safetensors |
Text encoder multimodal | CLIPLoader |
→ Qwen 2.5 VL 7B — un encodeur vision-langage (7 milliards de paramètres, FP8). Il comprend à la fois du texte et des images comme contexte de prompt, d’où le nœud spécial TextEncodeQwenImageEditPlus.
🎨 VAE
| Fichier | Type | Nœud |
|---|---|---|
qwen_image_vae.safetensors |
Variational AutoEncoder | VAELoader |
→ VAE propriétaire pour encoder/décoder les images dans l’espace latent de Qwen Image Edit.
🔧 LoRAs (deux adaptateurs fine-tunés)
| Fichier | Rôle | Force |
|---|---|---|
Qwen-Image-Edit-2509-Anything2RealAlpha.safetensors |
Stylisation réaliste — convertit tout type de rendu (3D, croquis…) en photo réaliste | 0.8 |
Qwen-Image-Edit-2509-Lightning-8steps-V1.0-bf16.safetensors |
Accélération — réduit le nombre de steps nécessaires (Lightning, 8 steps) | 1.0 |
Pour l’inpainting
🧠 Modèle de diffusion principal
| Fichier | Type | Nœud |
|---|---|---|
flux\flux-2-klein-9b.safetensors |
Diffusion model (UNet) | UNETLoader |
→ FLUX.2 Klein 9B — voilà l’origine du nom ! « Klein » est bien un modèle officiel de la famille FLUX2, développé par Black Forest Labs. C’est un modèle 9 milliards de paramètres, plus léger que FLUX.1 dev tout en conservant une haute qualité.
📝 Encodeur de texte (CLIP)
| Fichier | Type | Nœud |
|---|---|---|
flux\qwen_3_8b_fp8mixed.safetensors |
Text encoder (Qwen 3 8B) | CLIPLoader (type flux2) |
→ Qwen 3 8B en FP8 mixed — un LLM d’Alibaba utilisé comme encodeur de texte pour FLUX2 Klein. Beaucoup plus puissant qu’un CLIP classique pour la compréhension des prompts complexes.
🎨 VAE
| Fichier | Type | Nœud |
|---|---|---|
flux2-vae.safetensors |
Variational AutoEncoder | VAELoader |
→ VAE propriétaire de FLUX2, disponible sur HuggingFace (Comfy-Org/flux2-dev).
🔧 Nœud spécialisé (Custom Node)
| Node | Extension | Rôle |
|---|---|---|
Flux2KleinEnhancer |
capitan01R/ComfyUI-Flux2Klein-Enhancer |
Améliore le conditioning spécifiquement pour FLUX2 Klein (10 paramètres de contrôle : dampen, shift, etc.) |
→ C’est un custom node dédié à FLUX2 Klein, il post-traite le conditioning positif avant de l’envoyer au guider. Il faut installer l’extension ComfyUI-Flux2Klein-Enhancer.
◆ A propos de COMFYUI
ComfyUI s’impose comme un environnement de travail rigoureux pour l’architecte qui souhaite garder le contrôle sur la chaîne de génération. Les workflows multi-nœuds permettent une reproductibilité et une documentation du processus que les interfaces fermées ne permettent pas.
Les modèles spécialisés (ControlNet pour la géométrie, IP-Adapter pour les matériaux, Qwen pour l’éclairage) couvrent les principales étapes de représentation architecturale. L’enjeu est moins d’apprendre à dessiner des prompts que de comprendre quels modèles activer à quelle étape du projet.
La seconde famille d’outils testés (Google Gemini, Nano to Banana) offre une entrée plus directe et conversationnelle, particulièrement efficace pour la génération de planches de concours ou la conversion rapide de photos en représentations techniques. La complémentarité des deux approches semble prometteuse pour un atelier de projet.